


OpenLedge 研报:数据与模型可变现的 AI 链
作者:JacobZhao 来源:mirror
一、引言 | Crypto AI 的模型层跃迁
数据、模型与算力是 AI 基础设施的三大核心要素,类比燃料(数据)、引擎(模型)、能源(算力)缺一不可。与传统 AI 行业的基础设施演进路径类似,Crypto AI 领域也经历了相似的阶段。2024 年初,市场一度被去中心化 GPU 项目所主导 (Akash、Render、io.net 等 ),普遍强调「拼算力」的粗放式增长逻辑。而进入 2025 年后,行业关注点逐步上移至模型与数据层,标志着 Crypto AI 正从底层资源竞争过渡到更具可持续性与应用价值的中层构建。
通用大模型(LLM)vs 特化模型(SLM)
传统的大型语言模型(LLM)训练高度依赖大规模数据集与复杂的分布式架构,参数规模动辄 70B~500B,训练一次的成本常高达数百万美元。而 SLM(Specialized Language Model)作为一种可复用基础模型的轻量微调范式,通常基于 LLaMA、Mistral、DeepSeek 等开源模型,结合少量高质量专业数据及 LoRA 等技术,快速构建具备特定领域知识的专家模型,显著降低训练成本与技术门槛。
值得注意的是,SLM 并不会被集成进 LLM 权重中,而是通过 Agent 架构调用、插件系统动态路由、LoRA 模块热插拔、RAG(检索增强生成)等方式与 LLM 协作运行。这一架构既保留了 LLM 的广覆盖能力,又通过精调模块增强了专业表现,形成了高度灵活的组合式智能系统。
Crypto AI 在模型层的价值与边界
Crypto AI 项目本质上难以直接提升大语言模型(LLM)的核心能力,核心原因在于
技术门槛过高:训练 Foundation Model 所需的数据规模、算力资源与工程能力极其庞大,目前仅有美国(OpenAI 等)与中国(DeepSeek 等)等科技巨头具备相应能力。
开源生态局限:虽然主流基础模型如 LLaMA、Mixtral 已开源,但真正推动模型突破的关键依然集中于科研机构与闭源工程体系,链上项目在核心模型层的参与空间有限。
然而,在开源基础模型之上,Crypto AI 项目仍可通过精调特化语言模型(SLM),并结合 Web3 的可验证性与激励机制实现价值延伸。作为 AI 产业链的「周边接口层」,体现于两个核心方向:
可信验证层:通过链上记录模型生成路径、数据贡献与使用情况,增强 AI 输出的可追溯性与抗篡改能力。
激励机制: 借助原生 Token,用于激励数据上传、模型调用、智能体(Agent)执行等行为,构建模型训练与服务的正向循环。
AI 模型类型分类与 区块链适用性分析
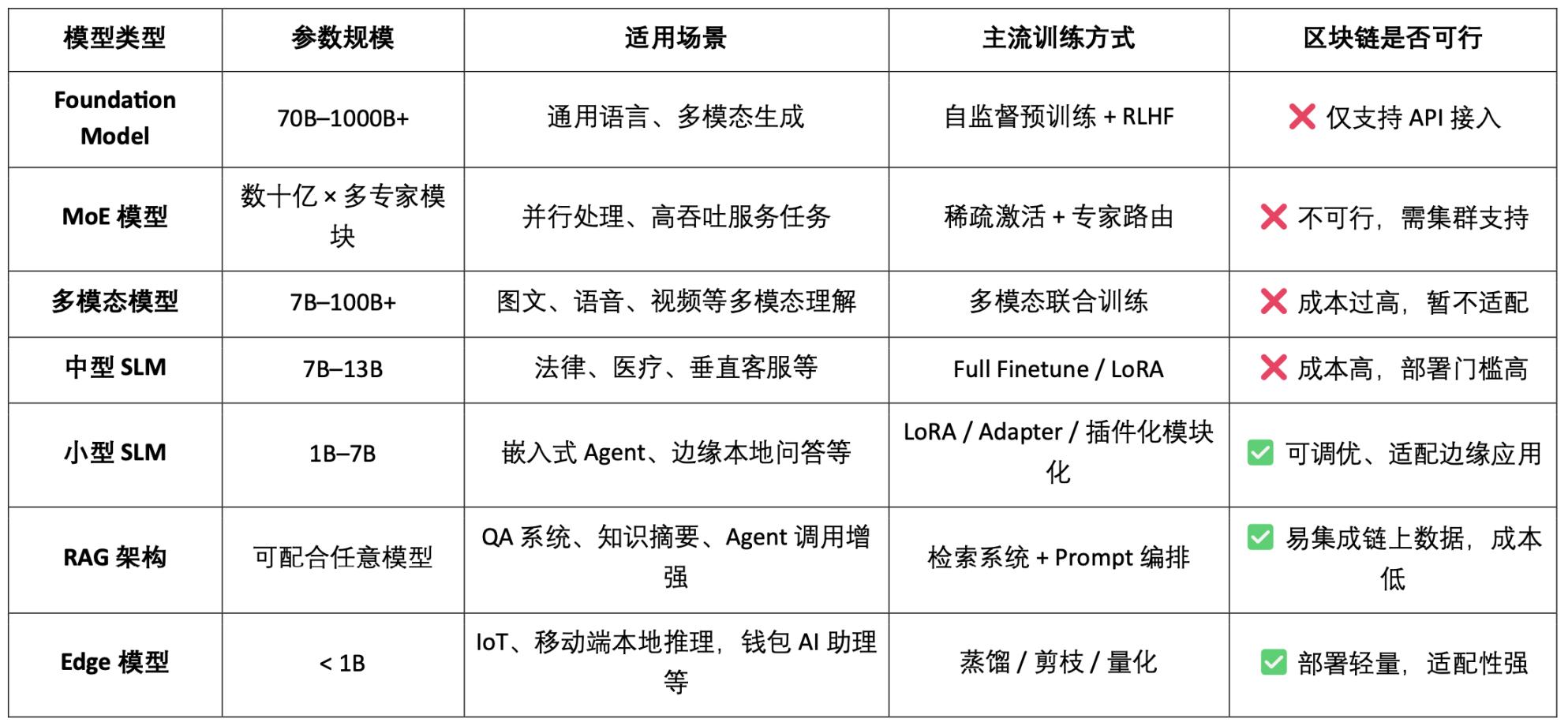
由此可见,模型类 Crypto AI 项目的可行落点主要集中在小型 SLM 的轻量化精调、RAG 架构的链上数据接入与验证、以及 Edge 模型的本地部署与激励上。结合区块链的可验证性与代币机制,Crypto 能为这些中低资源模型场景提供特有价值,形成 AI「接口层」的差异化价值。
基于数据与模型的区块链 AI 链,可对每一条数据和模型的贡献来源进行清晰、不可篡改的上链记录,显著提升数据可信度与模型训练的可溯性。同时,通过智能合约机制,在数据或模型被调用时自动触发奖励分发,将 AI 行为转化为可计量、可交易的代币化价值,构建可持续的激励体系。此外,社区用户还可通过代币投票评估模型性能、参与规则制定与迭代,完善去中心化治理架构。
二、项目概述 | OpenLedger 的 AI 链愿景
OpenLedger 是当前市场上为数不多专注于数据与模型激励机制的区块链 AI 项目。它率先提出「Payable AI」的概念,旨在构建一个公平、透明且可组合的 AI 运行环境,激励数据贡献者、模型开发者与 AI 应用构建者在同一平台协作,并根据实际贡献获得链上收益。
OpenLedger 提供了从「数据提供」到「模型部署」再到「调用分润」的全链条闭环,其核心模块包括:
Model Factory:无需编程,即可基于开源 LLM 使用 LoRA 微调训练并部署定制模型;
OpenLoRA:支持千模型共存,按需动态加载,显著降低部署成本;
PoA(Proof of Attribution):通过链上调用记录实现贡献度量与奖励分配;
Datanets:面向垂类场景的结构化数据网络,由社区协作建设与验证;
模型提案平台(Model Proposal Platform):可组合、可调用、可支付的链上模型市场。
通过以上模块,OpenLedger 构建了一个数据驱动、模型可组合的「智能体经济基础设施」,推动 AI 价值链的链上化。
而在区块链技术采用上,OpenLedger 以 OP Stack + EigenDA 为底座,为 AI 模型构建了高性能、低成本、可验证的数据与合约运行环境。
基于 OP Stack 构建: 基于 Optimism 技术栈,支持高吞吐与低费用执行;
在以太坊主网上结算: 确保交易安全性与资产完整性;
EVM 兼容: 方便开发者基于 Solidity 快速部署与扩展;
EigenDA 提供数据可用性支持:显著降低存储成本,保障数据可验证性。
相比于 NEAR 这类更偏底层、主打数据主权与 「AI Agents on BOS」 架构的通用型 AI 链,OpenLedger 更专注于构建面向数据与模型激励的 AI 专用链,致力于让模型的开发与调用在链上实现可追溯、可组合与可持续的价值闭环。它是 Web3 世界中的模型激励基础设施,结合 HuggingFace 式的模型托管、Stripe 式的使用计费与 Infura 式的链上可组合接口,推动「模型即资产」的实现路径。
三、OpenLedger 的核心组件与技术架构
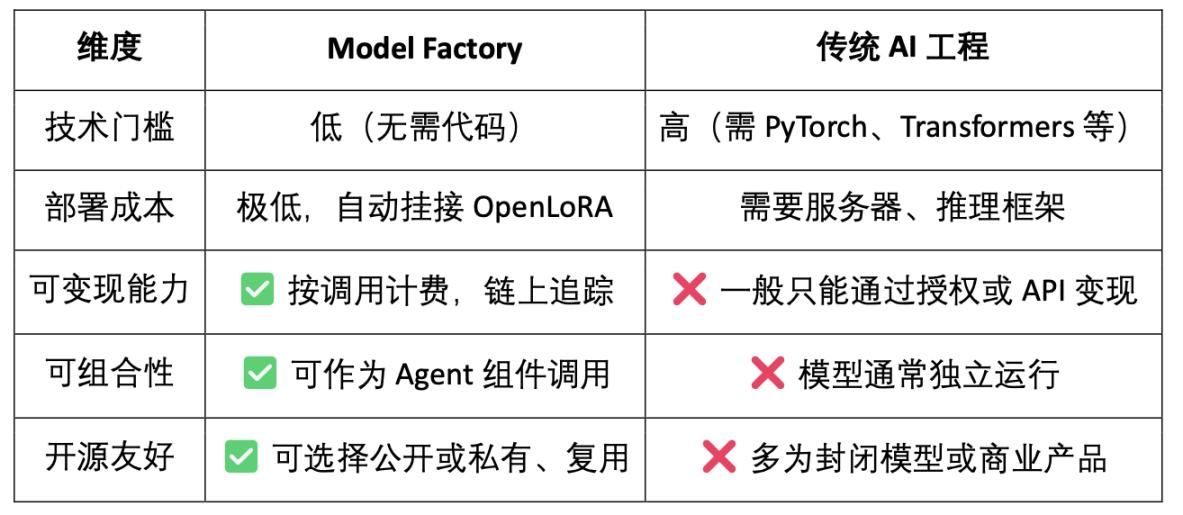
3.1 Model Factory,无需代码模型工厂
ModelFactory 是 OpenLedger 生态下的一个大型语言模型(LLM)微调平台。与传统微调框架不同,ModelFactory 提供纯图形化界面操作,无需命令行工具或 API 集成。用户可以基于在 OpenLedger 上完成授权与审核的数据集,对模型进行微调。实现了数据授权、模型训练与部署的一体化工作流,其核心流程包括:
数据访问控制: 用户提交数据请求,提供者审核批准,数据自动接入模型训练界面。
模型选择与配置: 支持主流 LLM(如 LLaMA、Mistral),通过 GUI 配置超参数。
轻量化微调: 内置 LoRA / QLoRA 引擎,实时展示训练进度。
模型评估与部署: 内建评估工具,支持导出部署或生态共享调用。
交互验证接口: 提供聊天式界面,便于直接测试模型问答能力。
RAG 生成溯源: 回答带来源引用,增强信任与可审计性。
Model Factory 系统架构包含六大模块,贯穿身份认证、数据权限、模型微调、评估部署与 RAG 溯源,打造安全可控、实时交互、可持续变现的一体化模型服务平台。
ModelFactory 目前支持的大语言模型能力简表如下:
LLaMA 系列:生态最广、社区活跃、通用性能强,是当前最主流的开源基础模型之一。
Mistral:架构高效、推理性能极佳,适合部署灵活、资源有限的场景。
Qwen:阿里出品,中文任务表现优异,综合能力强,适合国内开发者首选。
ChatGLM:中文对话效果突出,适合垂类客服和本地化场景。
Deepseek:在代码生成和数学推理上表现优越,适用于智能开发辅助工具。
Gemma:Google 推出的轻量模型,结构清晰,易于快速上手与实验。
Falcon:曾是性能标杆,适合基础研究或对比测试,但社区活跃度已减。
BLOOM:多语言支持较强,但推理性能偏弱,适合语言覆盖型研究。
GPT-2:经典早期模型,仅适合教学和验证用途,不建议实际部署使用。
虽然 OpenLedger 的模型组合并未包含最新的高性能 MoE 模型或多模态模型,但其策略并不落伍,而是基于链上部署的现实约束(推理成本、RAG 适配、LoRA 兼容、EVM 环境)所做出的「实用优先」配置。
Model Factory 作为无代码工具链,所有模型都内置了贡献证明机制,确保数据贡献者和模型开发者的权益,具有低门槛、可变现与可组合性的优点,与传统模型开发工具相比较:
对于开发者:提供模型孵化、分发、收入的完整路径;
对于平台:形成模型资产流通与组合生态;
对于应用者:可以像调用 API 一样组合使用模型或 Agent。
3.2 OpenLoRA,微调模型的链上资产化
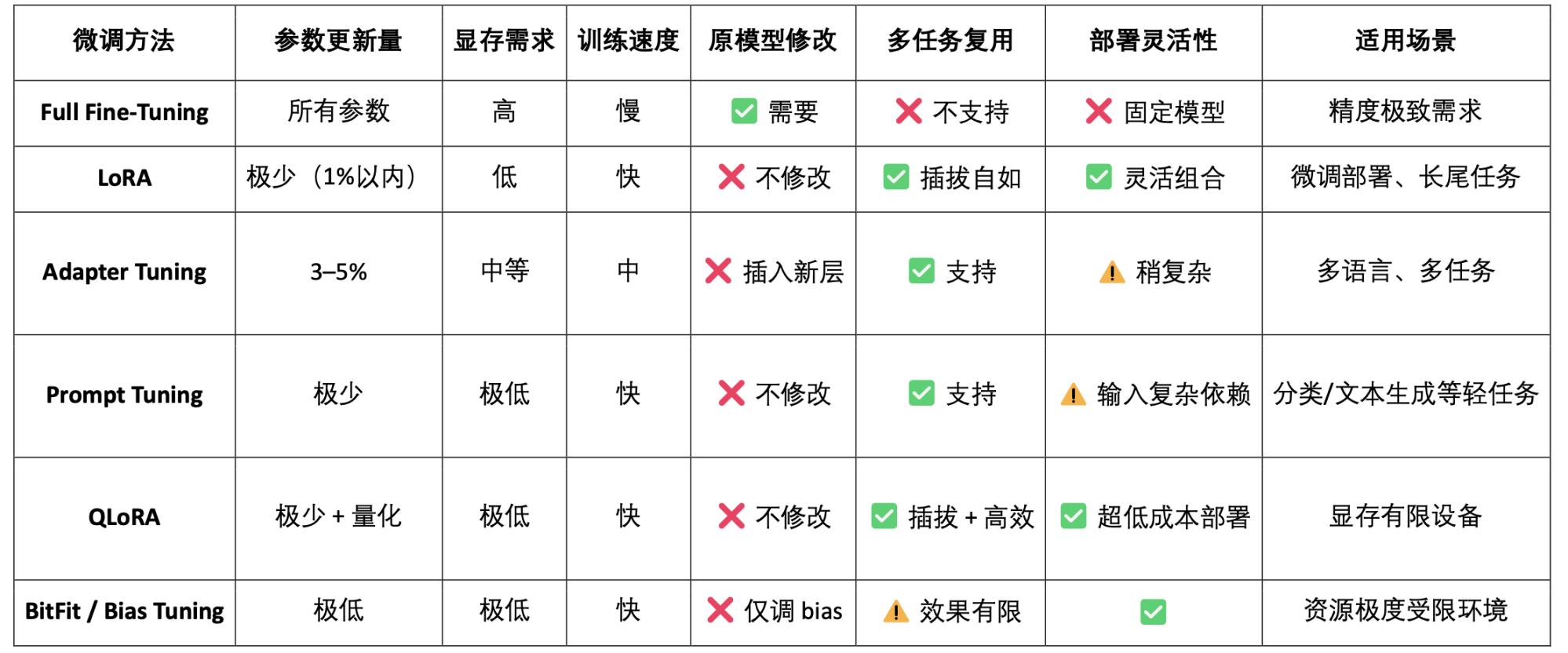
LoRA(Low-Rank Adaptation)是一种高效的参数微调方法,通过在预训练大模型中插入「低秩矩阵」来学习新任务,而不修改原模型参数,从而大幅降低训练成本和存储需求。传统大语言模型(如 LLaMA、GPT-3)通常拥有数十亿甚至千亿参数。要将它们用于特定任务(如法律问答、医疗问诊),就需要进行微调(fine-tuning)。LoRA 的核心策略是:「冻结原始大模型的参数,只训练插入的新参数矩阵。」,其参数高效、训练快速、部署灵活,是当前最适合 Web3 模型部署与组合调用的主流微调方法。
OpenLoRA 是 OpenLedger 构建的一套专为多模型部署与资源共享而设计的轻量级推理框架。它核心目标是解决当前 AI 模型部署中常见的高成本、低复用、GPU 资源浪费等问题,推动「可支付 AI」(Payable AI)的落地执行。
OpenLoRA 系统架构核心组件,基于模块化设计,覆盖模型存储、推理执行、请求路由等关键环节,实现高效、低成本的多模型部署与调用能力:
LoRA Adapter 存储模块 (LoRA Adapters Storage):微调后的 LoRA adapter 被托管在 OpenLedger 上,实现按需加载,避免将所有模型预载入显存,节省资源。
模型托管与动态融合层 (Model Hosting & Adapter Merging Layer):所有微调模型共用基础大模型(base model),推理时 LoRA adapter 动态合并,支持多个 adapter 联合推理(ensemble),提升性能。
推理引擎(Inference Engine):集成 Flash-Attention、Paged-Attention、SGMV 优化等多项 CUDA 优化技术。
请求路由与流式输出模块 (Request Router & Token Streaming): 根据请求中所需模型动态路由至正确 adapter, 通过优化内核实现 token 级别的流式生成。
OpenLoRA 的推理流程属于技术层面「成熟通用」的模型服务「流程,如下:
基础模型加载:系统预加载如 LLaMA 3、Mistral 等基础大模型至 GPU 显存中。
LoRA 动态检索:接收请求后,从 Hugging Face、Predibase 或本地目录动态加载指定 LoRA adapter。
适配器合并激活:通过优化内核将 adapter 与基础模型实时合并,支持多 adapter 组合推理。
推理执行与流式输出:合并后的模型开始生成响应,采用 token 级流式输出降低延迟,结合量化保障效率与精度。
推理结束与资源释放:推理完成后自动卸载 adapter,释放显存资源。确保可在单 GPU 上高效轮转并服务数千个微调模型,支持模型高效轮转。
OpenLoRA 通过一系列底层优化手段,显著提升了多模型部署与推理的效率。其核心包括动态 LoRA 适配器加载(JIT loading),有效降低显存占用;张量并行(Tensor Parallelism)与 Paged Attention 实现高并发与长文本处理;支持多模型融合(Multi-Adapter Merging)多适配器合并执行,实现 LoRA 组合推理(ensemble);同时通过 Flash Attention、预编译 CUDA 内核和 FP8/INT8 量化技术,对底层 CUDA 优化与量化支持,进一步提升推理速度并降低延迟。这些优化使得 OpenLoRA 能在单卡环境下高效服务数千个微调模型,兼顾性能、可扩展性与资源利用率。
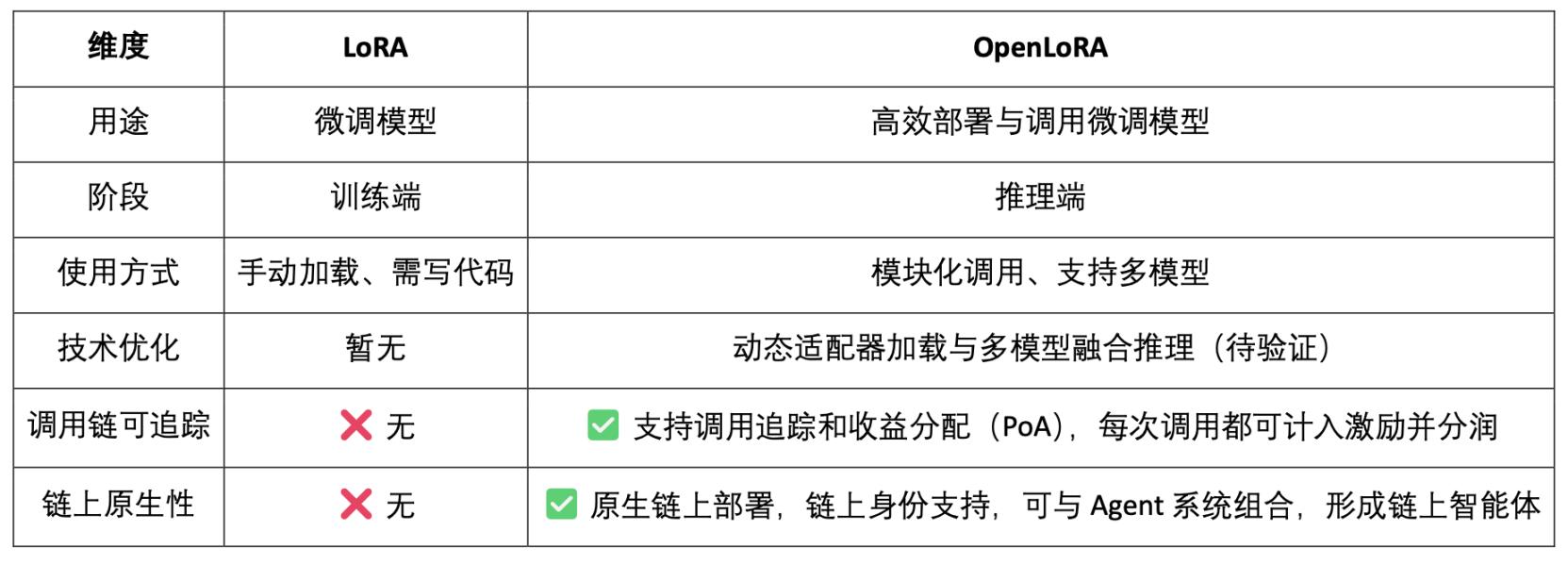
OpenLoRA 定位不仅是一个高效的 LoRA 推理框架,更是将模型推理与 Web3 激励机制深度融合,目标是将 LoRA 模型变成可调用、可组合、可分润的 Web3 资产。
模型即资产(Model-as-Asset):OpenLoRA 不只是部署模型,而是赋予每个微调模型链上身份(Model ID),并将其调用行为与经济激励绑定,实现「调用即分润」。
多 LoRA 动态合并 + 分润归属:支持多个 LoRA adapter 的动态组合调用,允许不同模型组合形成新的 Agent 服务,同时系统可基于 PoA(Proof of Attribution)机制按调用量为每个适配器精确分润。
支持长尾模型的「多租户共享推理」:通过动态加载与显存释放机制,OpenLoRA 能在单卡环境下服务数千个 LoRA 模型,特别适合 Web3 中小众模型、个性化 AI 助手等高复用、低频调用场景。
此外,OpenLedger 发布了其对 OpenLoRA 性能指标的未来展望,相比传统全参数模型部署,其显存占用大幅降低至 8–12GB;模型切换时间理论上可低于 100ms;吞吐量可达 2000+ tokens/sec;延迟控制在 20–50ms 。整体而言,这些性能指标在技术上具备可达性,但更接近「上限表现」,在实际生产环境中,性能表现可能会受到硬件、调度策略和场景复杂度的限制,应被视为「理想上限」而非「稳定日常」。
3.3 Datanets(数据网络),从数据主权到数据智能
高质量、领域专属的数据成为构建高性能模型的关键要素。Datanets 是 OpenLedger 」数据即资产「的基础设施,用于收集和管理特定领域的数据集,用于聚合、验证与分发特定领域数据的去中心化网络,为 AI 模型的训练与微调提供高质量数据源。每个 Datanet 就像一个结构化的数据仓库,由贡献者上传数据,并通过链上归属机制确保数据可溯源、可信任,通过激励机制与透明的权限控制,Datanets 实现了模型训练所需数据的社区共建与可信使用。
与聚焦数据主权的 Vana 等项目相比,OpenLedger 并不止于「数据收集」,而是通过 Datanets(协作式标注与归属数据集)、Model Factory(支持无代码微调的模型训练工具)、OpenLoRA(可追踪、可组合的模型适配器)三大模块,将数据价值延展至模型训练与链上调用,构建「从数据到智能(data-to-intelligence)」的完整闭环。Vana 强调「谁拥有数据」,而 OpenLedger 则聚焦「数据如何被训练、调用并获得奖励」,在 Web3 AI 生态中分别占据数据主权保障与数据变现路径的关键位置。
3.4 Proof of Attribution(贡献证明):重塑利益分配的激励层
Proof of Attribution(PoA)是 OpenLedger 实现数据归属与激励分配的核心机制,通过链上加密记录,将每一条训练数据与模型输出建立可验证的关联,确保贡献者在模型调用中获得应得回报,其数据归属与激励流程概览如下:
数据提交:用户上传结构化、领域专属的数据集,并上链确权。
影响评估:系统根据数据特征影响与贡献者声誉,在每次推理时评估其价值。
训练验证:训练日志记录每条数据的实际使用情况,确保贡献可验证。
激励分配:根据数据影响力,向贡献者发放与效果挂钩的 Token 奖励。
质量治理:对低质、冗余或恶意数据进行惩罚,保障模型训练质量。
与 Bittensor 子网架构结合评分机制的区块链通用型激励网络相比较,OpenLedger 则专注于模型层面的价值捕获与分润机制。PoA 不仅是一个激励分发工具,更是一个面向 透明度、来源追踪与多阶段归属 的框架:它将数据的上传、模型的调用、智能体的执行过程全程上链记录,实现端到端的可验证价值路径。这种机制使得每一次模型调用都能溯源至数据贡献者与模型开发者,从而实现链上 AI 系统中真正的「价值共识」与「收益可得」。
RAG(Retrieval-Augmented Generation) 是一种结合检索系统与生成式模型的 AI 架构,它旨在解决传统语言模型「知识封闭」「胡编乱造」的问题,通过引入外部知识库增强模型生成能力,使输出更加真实、可解释、可验证。RAG Attribution 是 OpenLedger 在检索增强生成(Retrieval-Augmented Generation)场景下建立的数据归属与激励机制,确保模型输出的内容可追溯、可验证,贡献者可激励,最终实现生成可信化与数据透明化,其流程包括:
用户提问 → 检索数据:AI 接收到问题后,从 OpenLedger 数据索引中检索相关内容。
数据被调用并生成回答:检索到的内容被用于生成模型回答,并被链上记录调用行为。
贡献者获得奖励:数据被使用后,其贡献者获得按金额与相关性计算的激励。
生成结果带引用:模型输出附带原始数据来源链接,实现透明问答与可验证内容。

OpenLedger 的 RAG Attribution 让每一次 AI 回答都可追溯至真实数据来源,贡献者按引用频次获得激励,实现「知识有出处、调用可变现」。这一机制不仅提升了模型输出的透明度,也为高质量数据贡献构建了可持续的激励闭环,是推动可信 AI 和数据资产化的关键基础设施。
四、OpenLedger 项目进展与生态合作
目前 OpenLedger 已上线测试网,数据智能层 (Data Intelligence Layer) 是 OpenLedger 测试网的首个阶段,旨在构建一个由社区节点共同驱动的互联网数据仓库。这些数据经过筛选、增强、分类和结构化处理,最终形成适用于大型语言模型(LLM)的辅助智能,用于构建 OpenLedger 上的领域 AI 模型。社区成员可运行边缘设备节点,参与数据采集与处理,节点将使用本地计算资源执行数据相关任务,参与者根据活跃度和任务完成度获得积分奖励。而这些积分将在未来转换为 OPEN 代币,具体兑换比例将在代币生成事件(TGE)前公布。
OpenLedger 测试网激励目前提供如下三类收益机制:
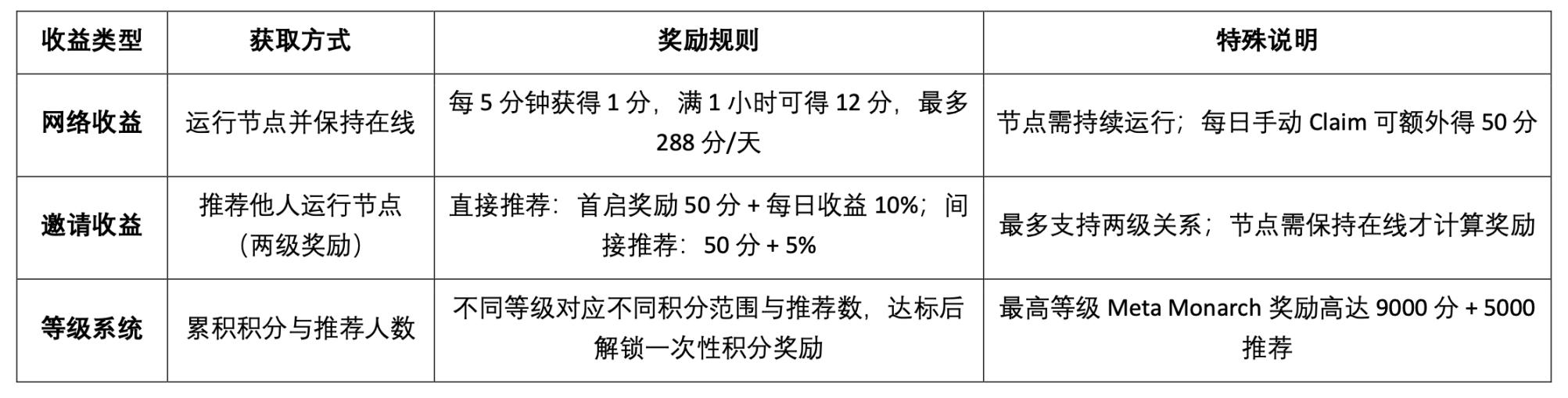
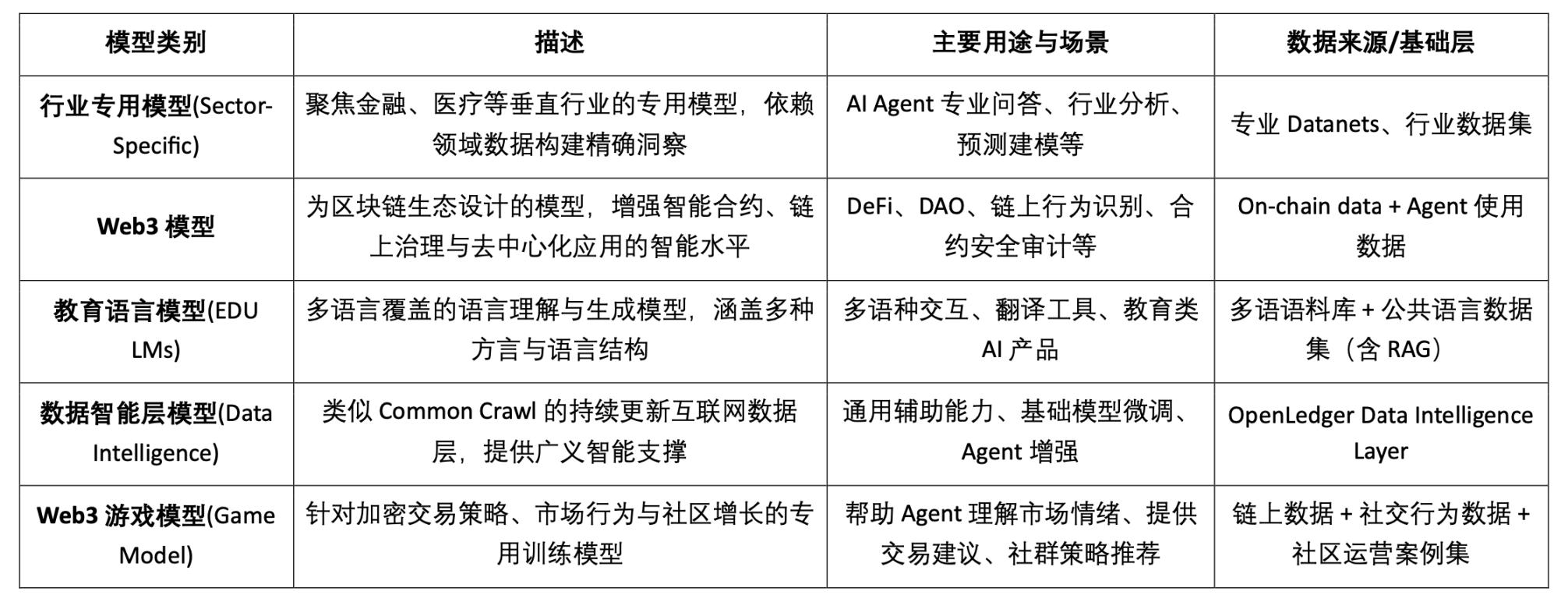
Epoch 2 测试网重点推出了 Datanets 数据网络机制,该阶段仅限白名单用户参与,需完成预评估以解锁任务。任务涵盖数据验证、分类等,完成后根据准确率和难度获得积分,并通过排行榜激励高质量贡献,官网目前提供的可参与数据模型如下:
而 OpenLedger 更为长远的路线图规划,从数据采集、模型构建走向 Agent 生态,逐步实现「数据即资产、模型即服务、Agent 即智能体」的完整去中心化 AI 经济闭环。
Phase 1 · 数据智能层 (Data Intelligence Layer): 社区通过运行边缘节点采集和处理互联网数据,构建高质量、持续更新的数据智能基础层。
Phase 2 · 社区数据贡献 (Community Contributions): 社区参与数据验证与反馈,共同打造可信的黄金数据集(Golden Dataset),为模型训练提供优质输入。
Phase 3 · 模型构建与归属声明 (Build Models & Claim): 基于黄金数据,用户可训练专用模型并确权归属,实现模型资产化与可组合的价值释放。
Phase 4 · 智能体创建 (Build Agents): 基于已发布模型,社区可创建个性化智能体(Agents),实现多场景部署与持续协同演进。
OpenLedger 的生态合作伙伴涵盖算力、基础设施、工具链与 AI 应用。其合作伙伴包括 Aethir、Ionet、0G 等去中心化算力平台,AltLayer、Etherfi 及 EigenLayer 上的 AVS 提供底层扩容与结算支持;Ambios、Kernel、Web3Auth、Intract 等工具提供身份验证与开发集成能力;在 AI 模型与智能体方面,OpenLedger 联合 Giza、Gaib、Exabits、FractionAI、Mira、NetMind 等项目共同推进模型部署与智能体落地,构建一个开放、可组合、可持续的 Web3 AI 生态系统。
过去一年,OpenLedger 在 Token2049 Singapore、Devcon Thailand、Consensus Hong Kong 及 ETH Denver 期间连续主办 Crypto AI 主题的 DeAI Summit 峰会,邀请了众多去中心化 AI 领域的核心项目与技术领袖参与。作为少数能够持续策划高质量行业活动的基础设施项目之一,OpenLedger 借助 DeAI Summit 有效强化了其在开发者社区与 Web3 AI 创业生态中的品牌认知与专业声誉,为其后续生态拓展与技术落地奠定了良好的行业基础。
五、融资及团队背景
OpenLedger 于 2024 年 7 月完成了 1120 万美元的种子轮融资,投资方包括 Polychain Capital、Borderless Capital、Finality Capital、Hashkey,以及多位知名天使投资人,如 Sreeram Kannan(EigenLayer)、Balaji Srinivasan、Sandeep(Polygon)、Kenny(Manta)、Scott(Gitcoin)、Ajit Tripathi(Chainyoda)和 Trevor。资金将主要用于推进 OpenLedger 的 AI Chain 网络建设、模型激励机制、数据基础层及 Agent 应用生态的全面落地。

OpenLedger 由 Ram Kumar 创立,他是 OpenLedger 的核心贡献者,同时是一位常驻旧金山的创业者,在 AI/ML 和区块链技术领域拥有坚实的技术基础。他为项目带来了市场洞察力、技术专长与战略领导力的有机结合。Ram 曾联合领导一家区块链与 AI/ML 研发公司,年营收超过 3500 万美元,并在推动关键合作方面发挥了重要作用,其中包括与沃尔玛子公司达成的一项战略合资项目。他专注于生态系统构建与高杠杆合作,致力于加速各行业的现实应用落地。
六、代币经济模型设计及治理
OPEN 是 OpenLedger 生态的核心功能型代币,赋能网络治理、交易运行、激励分发与 AI Agent 运营,是构建 AI 模型与数据在链上可持续流通的经济基础,目前官方公布的代币经济学尚属早期设计阶段,细节尚未完全明确,但随着项目即将迈入代币生成事件(TGE)阶段,其社区增长、开发者活跃度与应用场景实验正在亚洲、欧洲与中东地区持续加速推进:
治理与决策:OPEN 持有者可参与模型资助、Agent 管理、协议升级与资金使用的治理投票。
交易燃料与费用支付:作为 OpenLedger 网络的原生 gas 代币,支持 AI 原生的定制费率机制。
激励与归属奖励:贡献高质量数据、模型或服务的开发者可根据使用影响获得 OPEN 分润。
跨链桥接能力:OPEN 支持 L2 ↔ L1(Ethereum)桥接,提升模型和 Agent 的多链可用性。
AI Agent 质押机制:AI Agent 运行需质押 OPEN,表现不佳将被削减质押,激励高效、可信的服务输出。
与许多影响力与持币数量挂钩的代币治理协议不同,OpenLedger 引入了一种基于贡献价值的治理机制。其投票权重与实际创造的价值相关,而非单纯的资本权重,优先赋能那些参与模型和数据集构建、优化与使用的贡献者。这种架构设计有助于实现治理的长期可持续性,防止投机行为主导决策,真正契合其「透明、公平、社区驱动」的去中心化 AI 经济愿景。
七、数据、模型与激励市场格局及竞品比较
OpenLedger 作为「可支付 AI(Payable AI)」模型激励基础设施,致力于为数据贡献者与模型开发者提供可验证、可归属、可持续的价值变现路径。其围绕链上部署、调用激励和智能体组合机制,构建出具有差异化特征的模块体系,在当前 Crypto AI 赛道中独树一帜。虽然尚无项目在整体架构上完全重合,但在协议激励、模型经济与数据确权等关键维度,OpenLedger 与多个代表性项目呈现出高度可比性与协作潜力。
协议激励层:OpenLedger vs. Bittensor
Bittensor 是当前最具代表性的去中心化 AI 网络,构建了由子网(Subnet)和评分机制驱动的多角色协同系统,以 $TAO 代币激励模型、数据与排序节点等参与者。相比之下,OpenLedger 专注于链上部署与模型调用的收益分润,强调轻量化架构与 Agent 协同机制。两者激励逻辑虽有交集,但目标层级与系统复杂度差异明显:Bittensor 聚焦通用 AI 能力网络底座,OpenLedger 则定位为 AI 应用层的价值承接平台。
模型归属与调用激励:OpenLedger vs. Sentient
Sentient 提出的 「OML(Open, Monetizable, Loyal)AI」理念在模型确权与社区所有权上与 OpenLedger 部分思路相似,强调通过 Model Fingerprinting 实现归属识别与收益追踪。不同之处在于,Sentient 更聚焦模型的训练与生成阶段,而 OpenLedger 专注于模型的链上部署、调用与分润机制,二者分别位于 AI 价值链的上游与下游,具有天然互补性。
模型托管与可信推理平台:OpenLedger vs. OpenGradient
OpenGradient 侧重构建基于 TEE 和 zkML 的安全推理执行框架,提供去中心化模型托管与推理服务,聚焦于底层可信运行环境。相比之下,OpenLedger 更强调链上部署后的价值捕获路径,围绕 Model Factory、OpenLoRA、PoA 与 Datanets 构建「训练—部署—调用—分润」的完整闭环。两者所处模型生命周期不同:OpenGradient 偏运行可信性,OpenLedger 偏收益激励与生态组合,具备高度互补空间。
众包模型与评估激励:OpenLedger vs. CrunchDAO
CrunchDAO 专注于金融预测模型的去中心化竞赛机制,鼓励社区提交模型并基于表现获得奖励,适用于特定垂直场景。相较之下,OpenLedger 提供可组合模型市场与统一部署框架,具备更广泛的通用性与链上原生变现能力,适合多类型智能体场景拓展。两者在模型激励逻辑上互补,具备协同潜力。
社区驱动轻量模型平台:OpenLedger vs. Assisterr
Assisterr 基于 Solana 构建,鼓励社区创建小型语言模型(SLM),并通过无代码工具与 $sASRR 激励机制提升使用频率。相较而言,OpenLedger 更强调数据 - 模型 - 调用的闭环追溯与分润路径,借助 PoA 实现细粒度激励分配。Assisterr 更适合低门槛的模型协作社区,OpenLedger 则致力于构建可复用、可组合的模型基础设施。
模型工厂:OpenLedger vs. Pond
Pond 与 OpenLedger 同样提供「Model Factory」模块,但定位与服务对象差异显著。Pond 专注基于图神经网络(GNN)的链上行为建模,主要面向算法研究者与数据科学家,并通过竞赛机制推动模型开发,Pond 更加倾向于模型竞争;OpenLedger 则基于语言模型微调(如 LLaMA、Mistral),服务开发者与非技术用户,强调无代码体验与链上自动分润机制,构建数据驱动的 AI 模型激励生态,OpenLedger 更加倾向于数据合作。
可信推理路径:OpenLedger vs. Bagel
Bagel 推出了 ZKLoRA 框架,利用 LoRA 微调模型与零知识证明(ZKP)技术,实现链下推理过程的加密可验证性,确保推理执行的正确性。而 OpenLedger 则通过 OpenLoRA 支持 LoRA 微调模型的可扩展部署与动态调用,同时从不同角度解决推理可验证性问题 —— 它通过为每次模型输出附加归属证明(Proof of Attribution, PoA),追踪推理所依赖的数据来源及其影响力。这不仅提升了透明度,还为高质量数据贡献者提供奖励,并增强了推理过程的可解释性与可信度。简言之,Bagel 注重计算结果的正确性验证,而 OpenLedger 则通过归属机制实现对推理过程的责任追踪与可解释性。
数据侧协作路径:OpenLedger vs. Sapien / FractionAI / Vana / Irys
Sapien 与 FractionAI 提供去中心化数据标注服务,Vana 与 Irys 聚焦数据主权与确权机制。OpenLedger 则通过 Datanets + PoA 模块,实现高质量数据的使用追踪与链上激励分发。前者可作为数据供给上游,OpenLedger 则作为价值分配与调用中枢,三者在数据价值链上具备良好协同,而非竞争关系。

总结来看,OpenLedger 在当前 Crypto AI 生态中占据「链上模型资产化与调用激励」这一中间层位置,既可向上衔接训练网络与数据平台,也可向下服务 Agent 层与终端应用,是连接模型价值供给与落地调用的关键桥梁型协议。
八、结论 | 从数据到模型,AI 链的变现之路
OpenLedger 致力于打造 Web3 世界中的「模型即资产」基础设施,通过构建链上部署、调用激励、归属确权与智能体组合的完整闭环,首次将 AI 模型带入真正可追溯、可变现、可协同的经济系统中。其围绕 Model Factory、OpenLoRA、PoA 和 Datanets 构建的技术体系,为开发者提供低门槛的训练工具,为数据贡献者保障收益归属,为应用方提供可组合的模型调用与分润机制,全面激活 AI 价值链中长期被忽视的「数据」与「模型」两端资源。
OpenLedger 更像 HuggingFace + Stripe + Infura 的在 Web3 世界的融合体,为 AI 模型提供托管、调用计费与链上可编排的 API 接口。随着数据资产化、模型自治化、Agent 模块化趋势加速演进,OpenLedger 有望成为「Payable AI」模式下的重要中枢 AI 链。
相关文章

