


IOSG|游戏、AI 代理和加密货币的融合
作者|Sid @IOSG
Web3 游戏的现状
随着更新颖更具注意力的叙事方式的出现,Web3 游戏作为一个行业在一级和公开市场的叙事都退居其次。根据Delphi2024 年关于游戏产业的报告,Web3 游戏在一级市场的累计融资额不足 10 亿美元。这并不一定是坏事,这恰恰表明泡沫已经消退,现在的资本可能正在向更高质量的游戏兼容。下图就是一个明显的指标:
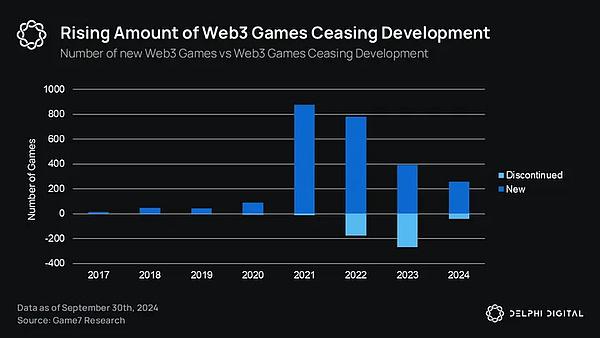
在整个 2024 年,Ronin 等游戏生态系统的用户数量大幅飙升,而且由于 Fableborn 等高品质新游戏的出现,几乎媲美 2021 年 Axie 的辉煌时期。
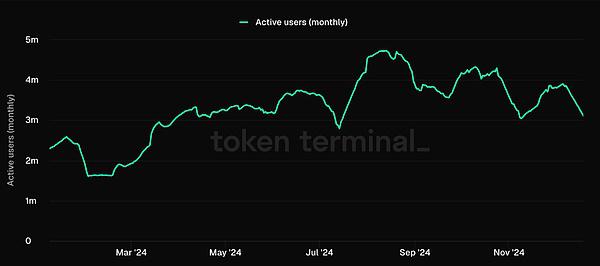
游戏生态系统(L1s、L2s、RaaS)正越来越像 Web3 的 Steam,它们掌控着生态系统内的分发,这也成为游戏开发商在这些生态系统中开发游戏的动力,因为这可以帮助他们获取玩家。根据他们之前的报告,Web3 游戏的用户获取成本比 Web2 游戏高出约 70%。
玩家粘性
留住玩家与吸引玩家同样重要,甚至更重要。虽然缺乏 Web3 游戏玩家留存率的数据,但玩家留存率与“Flow”的概念(匈牙利心理学家Mihaly Csikszentmihalyi提出的术语)密切相关。
“流状态”是一种心理学概念,在这种状态下,玩家在挑战和技能水平之间达到了完美的平衡。这就像 “进入状态”——时间似乎过得飞快,你完全沉浸在游戏中。
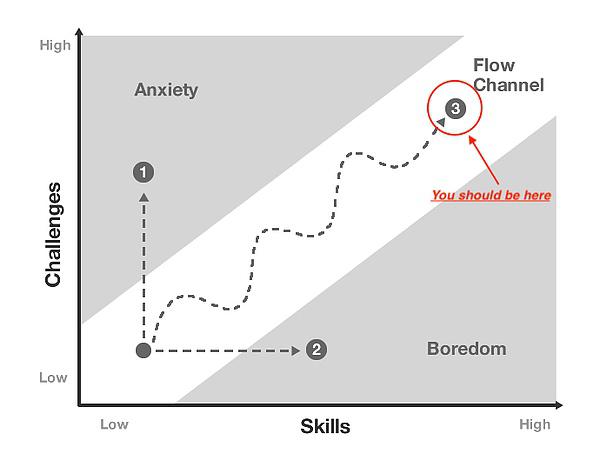
持续创造流状态的游戏往往具有更高的留存率,原因在于以下机制:
#进阶设计
游戏初期:简单挑战,建立信心
游戏中期:逐渐增加难度
游戏后期:复杂挑战,精通游戏
随着玩家技能的提高,这种细致的难度调整可让他们保持在自己的节奏范围内
#参与循环
短期:即时反馈(击杀、积分、奖励)
中期:关卡完成、每日任务
长期:角色发展、排名
这些嵌套循环可在不同时间范围内维持玩家的兴趣
#破坏流状态的因素则为:
1. 难度/复杂度设置不当:这可能是由于糟糕的游戏设计,或者甚至可能是由于玩家数量不足而导致的匹配失衡
2. 目标不明确:游戏设计因素
3. 反馈延迟:游戏设计和技术问题因
4. 侵入式货币化:游戏设计+产品
5. 技术问题/滞后

游戏与 AI 的共生
AI agents 可以帮助玩家获得这种流状态。在探讨如何实现这一目标之前,让我们先来了解一下什么样的代理适合运用到游戏领域:
LLM 与强化学习
代理和 NPC
游戏 AI 的关键在于:速度和规模。在游戏中使用 LLM 驱动的代理时,每个决策都需要调用一个庞大的语言模型。这就好比在迈出每一步之前都要有一个中间人。中间人很聪明,但等待他的回应会让一切变得缓慢痛苦。现在想象一下,在游戏中为数百个角色做这样的工作,不仅速度慢,而且成本很高。这就是我们尚未在游戏中看到大规模 LLM 代理的主要原因。我们目前看到的最大实验是在 Minecraft 上开发的 1000 个代理的文明。如果在不同的地图上有 10 万个并发代理,这将会非常昂贵。由于每添加一个新代理都会导致延迟,玩家也会受到流量中断的影响。这就破坏了流状态。
强化学习(RL)是一种不同的方式。我们把它想象成训练一个舞者,而不是通过耳麦给对方手把手的指导。通过强化学习,你需要在前期花时间教 AI 如何 “跳舞”,以及如何应对游戏中的不同情况。一旦训练有素,AI 就会自然流畅,在几毫秒内做出决定,而无需向上请求。你可以让数百个这样训练有素的代理在你的游戏中运行,每个代理都能根据自己的所见所闻独立做出决定。他们不像 LLM 代理那样能说会道或灵活机动,但他们做事快速高效。
当你需要这些代理协同工作时,RL 的真正魔力就显现出来了。LLM 代理需要冗长的 “对话 ”来协调,而 RL 代理则可以在训练中形成一种隐性的默契——就像一支一起训练了数月的橄榄球队。他们学会预测对方的动作,自然而然地进行协调。当这并不完美,有时它们会犯一些 LLM 不会犯的错误,但它们可以在 LLM 无法比拟的规模上运作。对于游戏应用来说,这种权衡总是有意义的。
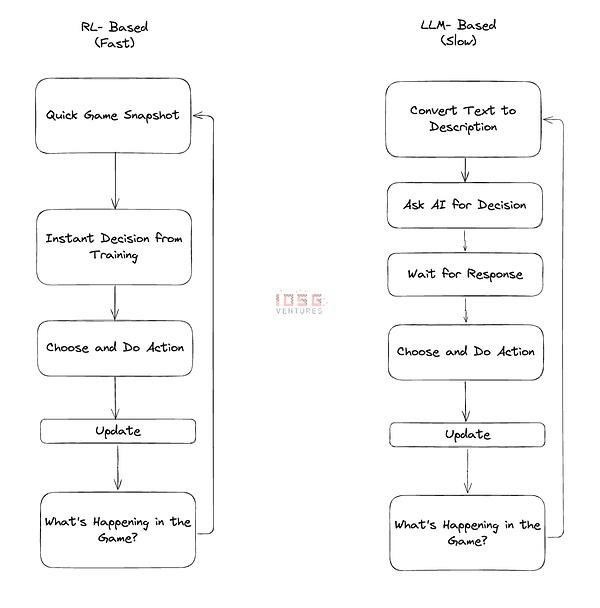
LLM 与强化学习
代理和 NPC
作为 NPC 的代理将解决当今许多游戏面临的第一个核心问题:玩家流动性。P2E 是第一个使用密码经济学解决玩家流动性问题的实验,我们都知道结果如何。
预先训练好的代理有两个作用:
填充多人游戏中的世界
维持世界中一组玩家的难度水平,使他们处于流状态
虽然这看起来非常明显,但构建起来却很困难。独立游戏和早期的 Web3 游戏没有足够的财力聘请人工智能团队,这为任何以 RL 为核心的代理框架服务商提供了机会。
游戏可以在试玩和测试期间与这些服务提供商合作,为游戏发布时的玩家流动性奠定基础。
如此一来,游戏开发者就可以把主要精力放在游戏机制上,使他们的游戏更加有趣。尽管我们喜欢将代币融入游戏,但游戏终究是游戏,游戏应该是有趣的。
代理玩家
元宇宙的回归?
世界上玩家最多的游戏之一《英雄联盟》有一个黑市,玩家在黑市上用最好的属性训练自己的人物,而游戏禁止他们这样做。
这有助于形成游戏角色和属性作为 NFT 的基础,从而创建一个市场来实现这一点。
如果出现一个新的 “玩家 ”子集,作为这些人工智能代理的教练呢?玩家可以指导这些人工智能代理,并以不同的形式将其货币化,例如赢得比赛,还可以充当电竞选手或激情玩家的 “训练伙伴”。
LLM 与强化学习
元宇宙的回归?
元宇宙的早期版本可能只是创造了另一种现实,而不是理想的现实,因此没有达到目标。AI agents 帮助元宇宙居民创造一个理想世界 —— 逃离。
在我看来,这正是基于 LLM 的代理可以大显身手的地方。也许有人可以在自己的世界中加入预先训练好的代理,这些代理都是领域专家,可以就他们喜欢的事物进行对话。如果我创建了一个经过 1000 小时 Elon Musk 访谈训练的代理,而用户希望在他们的世界中使用这个代理的实例,那么我就可以为此获得奖励。这样就能创造新的经济。
有了 Nifty Island 这样的元宇宙游戏,这就可以成为现实。
在 Today: The Game 中,团队已经创建了一个基于 LLM 的 AI agent,名为 “Limbo”(发布了投机性代币),其愿景是多个代理在这个世界中自主互动,同时我们可以观看 24x7 的直播流。

Crypto 如何与之融合?
Crypto 可以通过不同方式帮助解决这些问题:
玩家贡献自己的游戏数据,以改进模型,获得更好的体验,并因此获得奖励
协调角色设计师、训练师等多方利益相关者,创建最好的游戏内代理
创建一个拥有游戏内代理所有权的市场,并将其货币化
有一个团队正在做这些事情,而且做得更多:ARC Agents。他们正在解决上面提到的所有问题。
他们拥有 ARC SDK,允许游戏开发人员根据游戏参数创建类似人类的人工智能代理。通过非常简单的集成,它就能解决玩家流动性问题,清理游戏数据并将其转化为见解,还能通过调整难度级别帮助玩家在游戏中保持流状态。为此,他们使用了强化学习(Reinforcement Learning)技术。
他们最初开发了一款名为 “AI 竞技场”(AI Arena)的游戏,在这款游戏中,基本上是在训练你的 AI 角色进行战斗。这帮助他们形成了一个基准学习模型,该模型构成了 ARC SDK 的基础。这就形成了某种类似 DePIN 的飞轮:
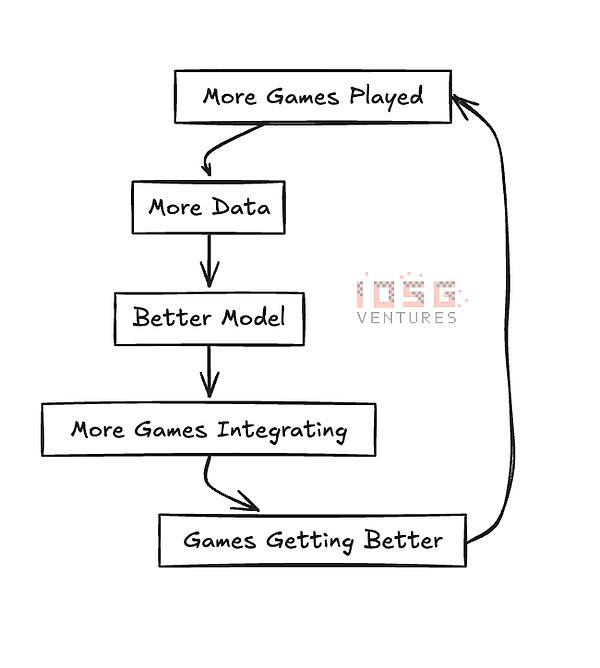
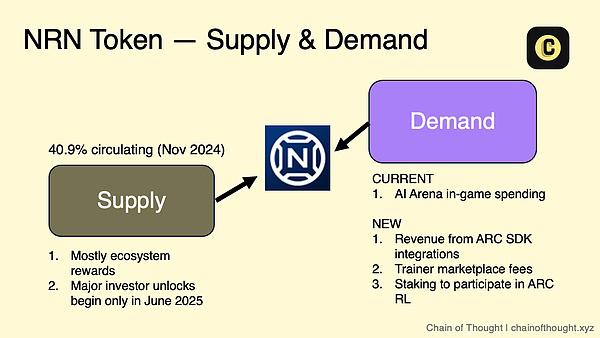
所有这一切都以他们的生态系统代币 $NRN 作为协调。Chain of Thought团队在他们关于 ARC 代理的文章中对此做了很好的解释:
像Bounty这样的游戏正采取 agent-first 的方法,在一个狂野的西部世界中从头开始建立代理。

结语
AI agents、游戏设计和 Crypto 的融合不仅仅是另一种技术趋势,它还有可能解决困扰独立游戏的各种问题。AI agents 在游戏领域的妙处在于,它们增强了游戏的乐趣所在——良好的竞争、丰富的互动,以及让人流连忘返的挑战。随着 ARC 代理等框架的成熟和更多游戏集成 AI agents,我们很可能会看到全新的游戏体验出现。想象一下,世界之所以充满活力,并不是因为里面有其他玩家,而是因为里面的代理能够与社区一起学习和进化。
我们正在从一个“play-to-earn”转向一个更令人兴奋的时代:既富含真正的乐趣,又可无限扩展的游戏。对于关注这一领域的开发者、玩家和投资者来说,未来几年将非常精彩。2025 年及以后的游戏不仅在技术上更加先进,而且从根本上讲,它们将比我们以前看到的任何游戏都更吸引人、更易参与、更有生命力。
相关文章

